CVR-LLM is to capitalize on VLMs' visual perception proficiency and LLMs' extensive reasoning capability.
Recent advancements in Vision-Language (VL) research have sparked new benchmarks for complex visual reasoning, challenging models' advanced reasoning ability. Traditional Vision-Language models (VLMs) perform well in visual perception tasks while struggling with complex reasoning scenarios. Conversely, Large Language Models (LLMs) demonstrate robust text reasoning capabilities; however, they lack visual acuity. To bridge this gap, we propose Complex Visual Reasoning Large Language Models (CVR-LLM), capitalizing on VLMs' visual perception proficiency and LLMs' extensive reasoning capability. Unlike recent multimodal large language models (MLLMs) that require a projection layer, our approach transforms images into detailed, context-aware descriptions using an iterative self-refinement loop and leverages LLMs' text knowledge for accurate predictions without extra training. We also introduce a novel multi-modal in-context learning (ICL) methodology to enhance LLMs' contextual understanding and reasoning. Additionally, we introduce Chain-of-Comparison (CoC), a step-by-step comparison technique enabling contrasting various aspects of predictions. Our CVR-LLM presents the first comprehensive study across a wide array of complex visual reasoning tasks and achieves SOTA performance among all.
To evaluate the effectiveness of our proposed method, we conduct a comprehensive test in complex visual reasoning areas. Our evaluation included WinoGAViL (4373 samples), Winoground (400 samples), Whoops (500 samples), VCR (2653 out of over 26k samples, selecting a random 10%), and NYCCC (528 samples), providing a broad assessment of our approach's capabilities.
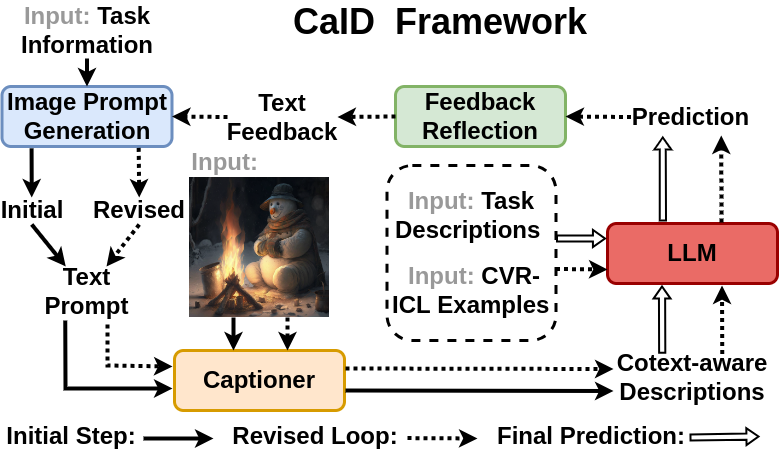
Context-Aware Image Description. Our CaID framework optimizes the process of creating context-aware image descriptions through a dual-loop self-refinement approach. Initially, it leverages task-specific details and LLM insights to craft precise image prompts. These initial prompts are designed to distill essential task-related information, guiding the captioner in producing descriptions that are not only cover image content but also deeply aligned with the task's requirements. In the second loop, our approach is crafted to encapsulate essential task-related details as well as LLMs' feedback, enhancing description generation with LLMs' vast knowledge. Specifically, it merges initial descriptions with task specifics and CVR-ICL examples into a task-focused prompt, guiding LLMs to make more precise predictions. These predictions are then treated as pseudo labels, asking LLMs to design further inquiries for deeper insights around them.
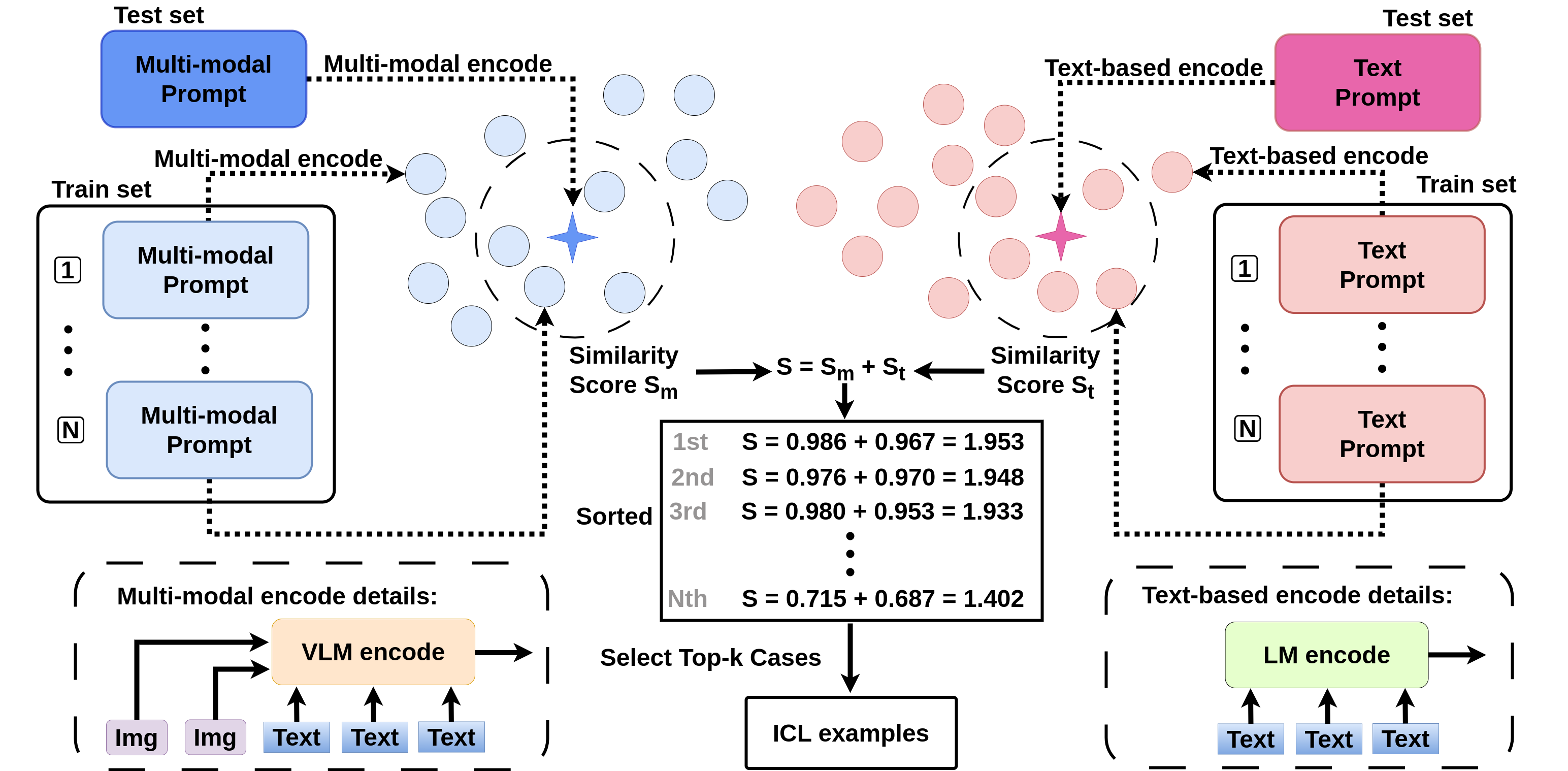
Complex Visual Reasoning ICL. we propose the complex visual reasoning ICL, which aims to select in-context examples for LLMs by effectively integrating both text and multi-modal components. This dual analysis enables our LLM to more effectively select contextually relevant examples. ensuring a balanced integration of text and multi-modal insights for enhanced in-context learning.
The comparison of our CVR-LLM with popular VLMs and MM LLMs on five complex visual reasoning tasks. Notably, MLLMs like LLaVA and MiniGPT4 exhibit limitations in handling tasks involving multiple images or computing image-text similarity scores, resulting in their performance being unavailable for tasks like WinoGAViL and Winoground.
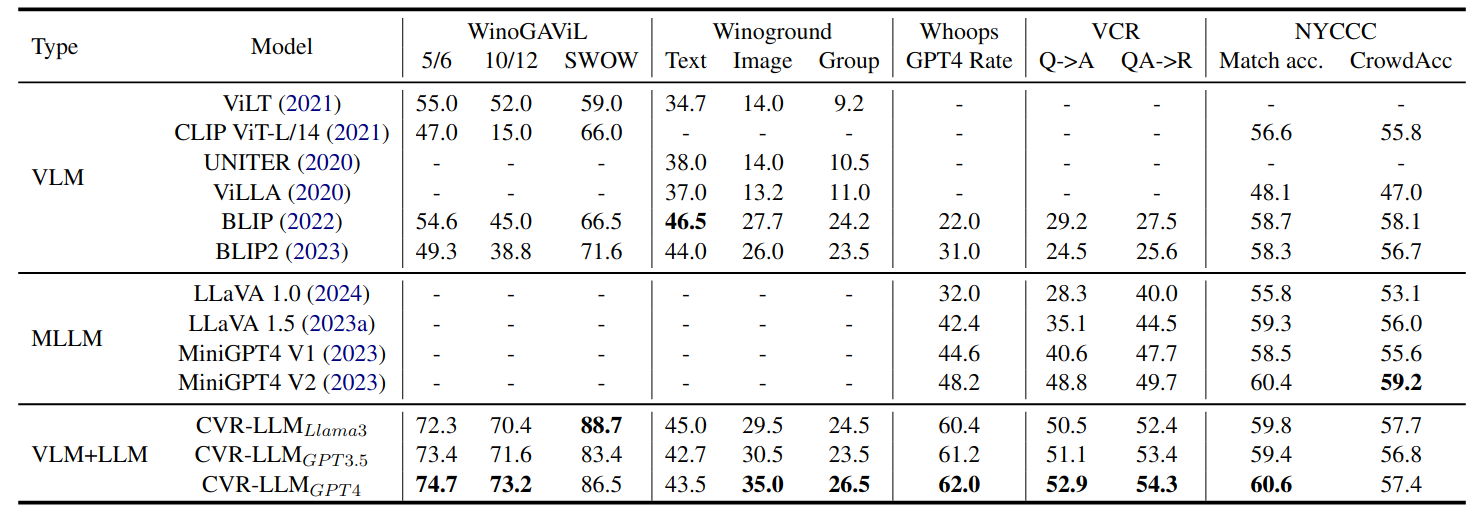
Ablation Studies.We examine the individual contributions of the components within our framework CVR-LLM(GPT4). The experimental findings suggest that the CVR-ICL module significantly boosts the inference performance of LLMs compared to using context-aware image descriptions alone, with the exception of the NYCCC dataset (It may be due to NYCCC's focus on humor, where precise descriptions are more critical). This highlights the CVR-ICL module's effectiveness in enhancing LLM capabilities across various tasks. In addition, our comprehensive method, CVR-LLM, which integrates both context-aware descriptions and CVR-ICL, achieves a substantial enhancement in performance relative to the baseline.

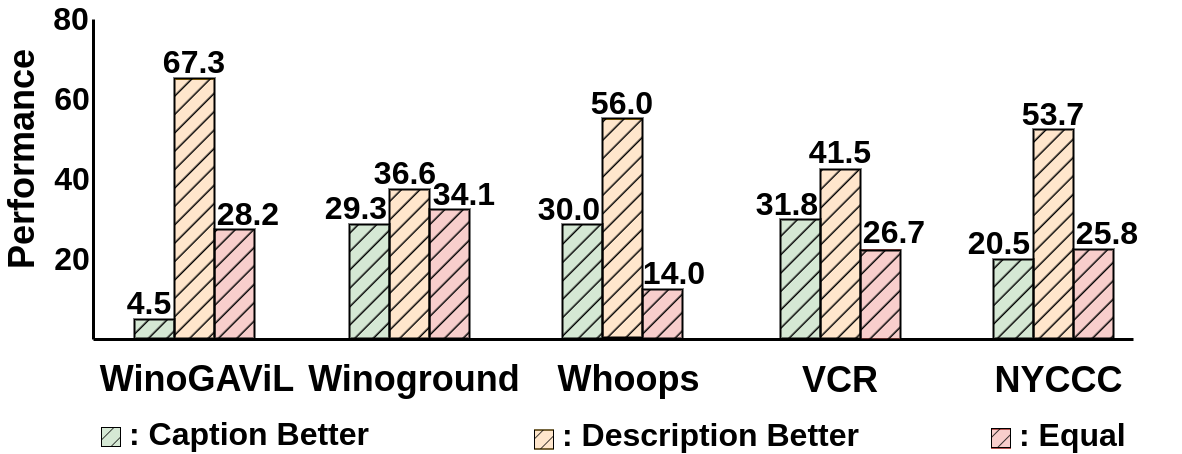
Context-Aware Image Description vs General Image Caption.we investigate CaID's impact at an abstract level and design a novel method to quantitatively demonstrate the semantic gap between context-aware image descriptions and general image captions. we use GPT4 to evaluate the relative effectiveness between two kinds of expressions with the prompt: "Evaluate the equivalence of the following two options for the task XXX. Option A: XXX; Option B: XXX. Please return True if Option B is better than Option A in answering questions; return False if the opposite is true; return Equal if they are the same for the question.". The comparison result is shown as below.
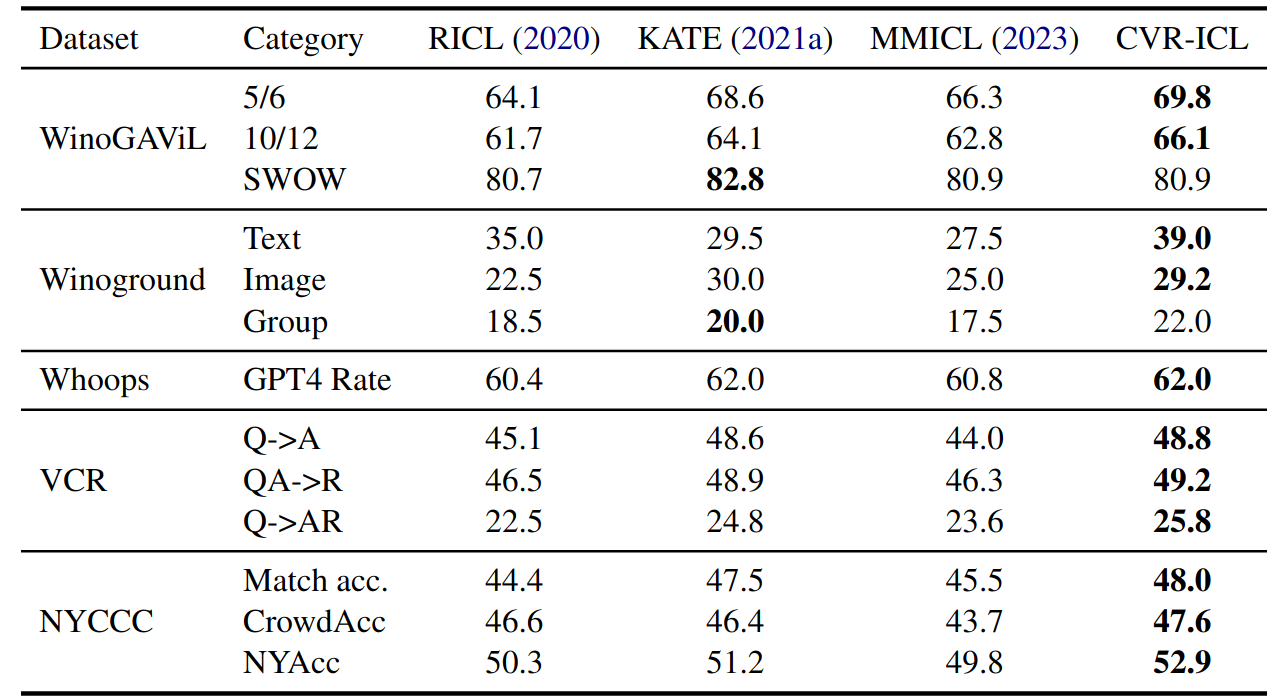
Complex Visual Reasoning ICL vs Other ICL.The CVR-ICL is designed to optimize the selection of in-context exemplars within a multi-modal environment, thereby enhancing the reasoning abilities of LLMs. This innovative method is contrasted with three alternative configurations: Random In-Context Learning (RICL), KATE, and Multi-modal Similar In-Context Learning (MMICL). To ensure a fair comparison, we utilized general image captions across all models to test performance for eliminating the effect of our context-aware image descriptions.
To showcase our approach capabilities, we present qualitative results. It illustrates how LLMs leverage contextual information to ask more relevant and insightful questions tailored the specific tasks. For instance, when provided with an image of the chess piece, the LLMs might ask "What does the chess piece look like?". Subsequently, the captioner model generates contextually appropriate descriptions, such as "A chess piece that looks like a unicorn.". This synergy enhances the LLM's decision-making process, making it more precise and context-aware.
@article{li2024enhancing,
title={Enhancing Advanced Visual Reasoning Ability of Large Language Models},
author={Li, Zhiyuan and Liu, Dongnan and Zhang, Chaoyi and Wang, Heng and Xue, Tengfei and Cai, Weidong},
journal={arXiv preprint arXiv:2409.13980},
year={2024}
}